{kind=link}
Scalable nonparametric clustering with unified marker gene selection for single-cell RNA-seq data
 Computational Methods
Computational Methods
 Genomics
Genomics
 Alex K. Shalek
Alex K. Shalek
 Andrew Navia
Andrew Navia
 Michelle Ramseier
Michelle Ramseier
 Peter Winter
Peter Winter
bioRxiv
February, 2024
Abstract
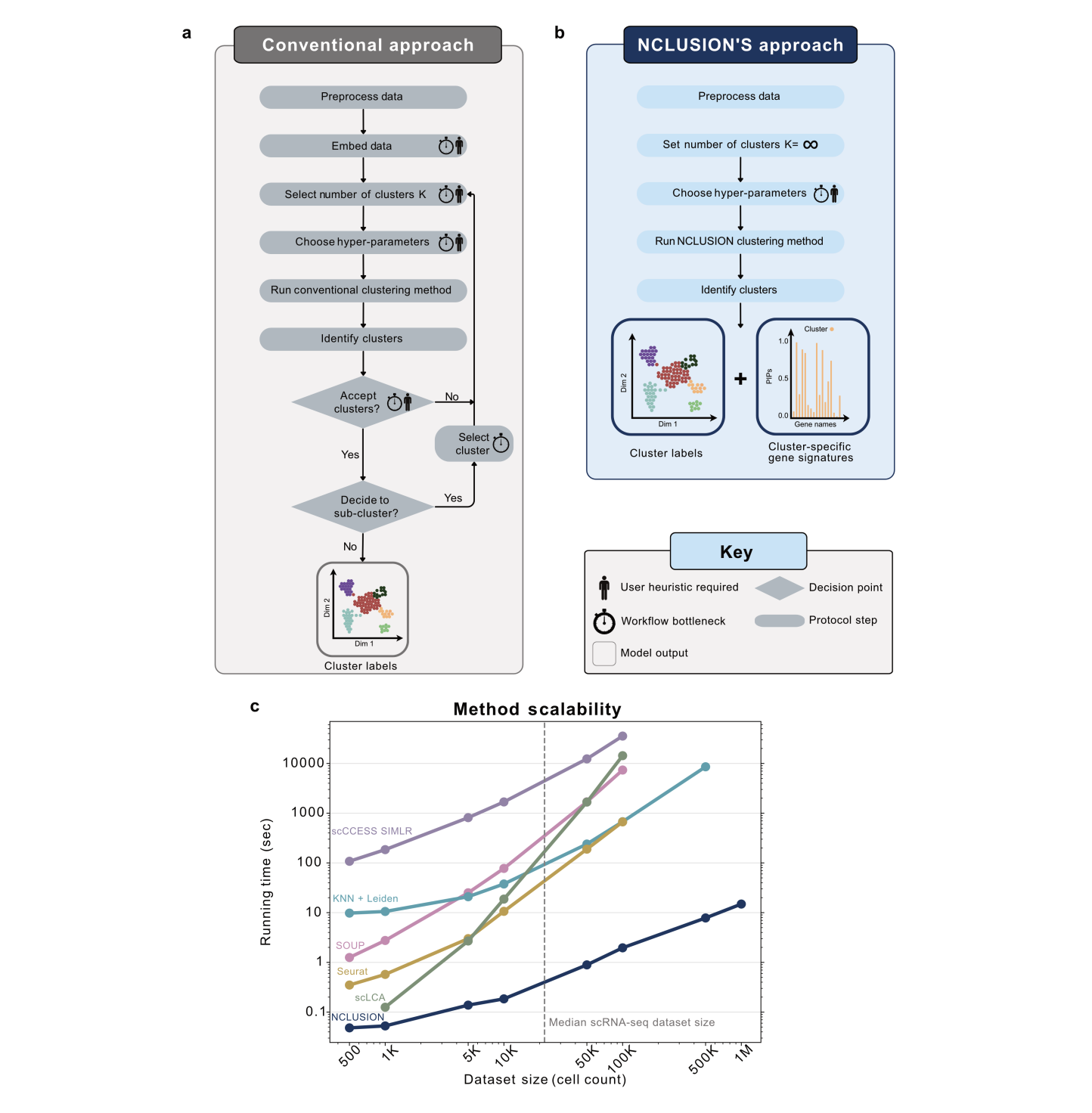
Clustering is commonly used in single-cell RNA-sequencing (scRNA-seq) pipelines to characterize cellular heterogeneity. However, current methods face two main limitations. First, they require user-specified heuristics which add time and complexity to bioinformatic workflows; second, they rely on post-selective differential expression analyses to identify marker genes driving cluster differences, which has been shown to be subject to inflated false discovery rates. We address these challenges by introducing nonparametric clustering of single-cell populations (NCLUSION): an infinite mixture model that leverages Bayesian sparse priors to identify marker genes while simultaneously performing clustering on single-cell expression data. NCLUSION uses a scalable variational inference algorithm to perform these analyses on datasets with up to millions of cells. By analyzing publicly available scRNA-seq studies, we demonstrate that NCLUSION (i) matches the performance of other state-of-the-art clustering techniques with significantly reduced runtime and (ii) provides statistically robust and biologically relevant transcriptomic signatures for each of the clusters it identifies. Overall, NCLUSION represents a reliable hypothesis-generating tool for understanding patterns of expression variation present in single-cell populations.